AP Statistics: Chapter 12.2: Inference for TWO Proportions
In two-sample problems, we want to compare responses ot two independent samples. In chapter 11, we compare two means using a two-sample t procedures. In chapter 15, we will compare two standard deviations using an F statistic. In a two-sample proportion problem (this section) we want to compare two populations or the responses of two different treatments based on two independent samples.
We will now develop methods to compare the proportions of “successes” in two groups.
We will use subscripts to denote the information coming from each of the two populations. Population Population proportion Sample size Sample proportion
We typically compare populations by drawing inferences about the DIFFERENCE 1
population proportions. Of course, we’re not going to know the true values of these, so we use the test statistic that estimates this difference, namely 1
p has its own sampling distribution. Here’s what you need to know (already
know) about them in order to do inference correctly.
The mean of the sampling distribution for 1
p p . ˆp ˆp is an unbiased
p is the sum of the variances of 1
When the sample size is large, the distribution of 1
Each sample must be taken from independent random samples. Populations must still be at least 10 1
n . The only difference from single proportions is that 1
bigger (not 10 or bigger). Be sure to check them for both.
Calculating confidence intervals and doing significant tests will have the same feel as before, just with different equations. Here they are:
Again, we’re using our sample proportions
p as approximations of the true population
and is called the pooled proportion Example 1: A study was conducted to determine the effect of preschool on later use of social services. It identified the proportion of two groups who needed social services later in life. The data is as follows: Population Population Number needing Description Proportion
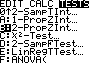
Find a 95% confidence interval. First check the assumptions (It’s a big drag, but you MUST show this step.)Assumptions:
Our distribution is approximately normal by the Central Limit Theorem because each sample size is
We’ll assume both samples were take from a random sample of the populations of people who
attended preschool and those who didn’t (the control).
We’ll also assume both populations of interest are at least 610 (for control) and 620 (for others).
p 62.613 38, and
q 62.387 24 . All of these numbers are greater than 5, so our inference results will be
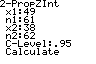
Using the following equation for a 95% confidence interval with *
z 1.960 , ˆp ˆp
We get our interval of 0.033,0.347 .
Conclusion: I am 95% confident that the percent needing social services is between 3.3% and 34.7% lower among people who attended preschool. Significance tests for 1
This is where things get a bit different. Try to follow the logic, and it will make sense.
Like before, we set up a hypothesis test. Our null hypothesis says EITHER that the difference of our two proportions is zero, but it is more common (and easier) to say the two proportions are the same. That is
Remember that for significance tests, we use 1
p , the true population proportions, and NOT 1
p . Significance tests make some claim about the populations, not the samples. You will not know these values, so the hypothesis will be in terms of 1 p and 2
The alternative hypothesis states the kind of difference between the two population proportions we expect, or what we are testing for, namely
In order to perform a significance test, we use a pooled sample proportion. Why pooled? Well, if our null hypothesis is true, then both samples come from a single population with a certain unknown proportion p. We act as if this is the case, so we combine the two samples and examine a “new” collective ˆp .
We use this pooled ˆp in place of 1
p in the formula for the standard error (SE). We use this to get a
z statistic that has the standard normal distribution when H0 is true. So here’s the formula for the z test statistic when testing H0 : 1
Once we find this z test statistic (in fact, we most often find it with the calculator), we use it exactly as you’d expect. We must still check that 1
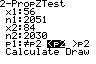
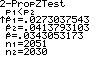
n ˆq2 be 5 or bigger. Example 2: The Helsinki Heart Study wished to find out if a drug used to lower blood cholesterol would reduce heart attacks. They randomly assigned 2051 middle-aged men to a group that took gemfibrozil to reduce cholesterol and 2030 men to a placebo group. During the next 5 years, 56 men in the gemfibrozil group had heart attacks while 84 men in the placebo group did. Did the gemgibrozil help reduce heart attacks in those that took it?
State: “We will use a “Two-sample proportion z test.”
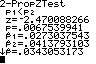
Calculate and define your proportions.
Set up the null and alternative hypotheses:
p p2 (the two populations had heart attacks at same proportion)
p (the gemfibrozil group has smaller proportion of heart attacks). q and make sure they’re 5 or bigger. Then state your other
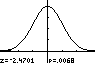
assumptions (normality, SRS, and random sample). z 2.470 and p 0.0068
Interpret your results and write your conclusion.
Since our p-value of 0.0068 is less than 0.01, the results are statistically significant at the 1% ( 0.01) level. There is strong evidence that gemfibrozil reduced the rate of heart attacks. The large samples in the Helsinki Heart study helped the study get highly significant results.
2900 Fairview Park Dr • Falls Church VA • 22042-4513 • USA Tel: 800-262-8200 • +1 703-741-5500 • Fax: +1 703-741-6037 www.chemtrec.com CHEMTREC® Agreement – Global Authorization CHEMTREC Agreement – Global Authorization Version I.ii; January 1, 2014 I. GENERAL AGREEMENT - The American Chemistry Council (the “Council”) hereby agrees to provide the re
PREPARATION OF ASPIRIN AND ACETAMINOPHEN 1996 by David A. Katz. All rights reserved. Reproduction permitted for education purposes as long as original copyright is included. OBJECT To synthesize some common pain relievers: aspirin and acetaminophen. To determine the purity of the aspirin or acetaminophen. THEORY Aspirin, acetylsalicylic acid, was first synthesized in 1893 by
 Example 1: A study was conducted to determine the effect of preschool on later use of social services. It
Example 1: A study was conducted to determine the effect of preschool on later use of social services. It 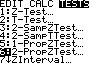
 z 2.470 and p 0.0068
Interpret your results and write your conclusion.
z 2.470 and p 0.0068
Interpret your results and write your conclusion.